
AI agents are the main objective in 2025. Everyone including enterprises are building AI agent systems by utilizing cloud providers or third party solutions. These platforms provide reasonable capabilities to create simple to medium complex level systems.
Take the GitHub issue solver example. The promise is simple: developer creates an issue, AI agent reads the codebase, understands the problem, writes the fix, tests it, and submits a PR. In practice? The agent misunderstands requirements, writes code that doesn’t compile, or changes the code differently :).
Throughout the software development history, as I read and watch, I’ve never seen such tendency to rely on high entropy after JS :). We’re essentially throwing more complexity at a fundamentally unstable foundation hoping that somehow, adding more moving parts will create reliability.
Even though LLMs are improving over time, this doesn’t change the fact that they are just random machines that select the most probable outcome to an input. Therefore, the error margin always exists.
Current Optimizations?
Current “solutions” all follow the same pattern: optimize the LLM. Feed it more relevant context, use more powerful models, add sophisticated prompting techniques. RAG systems try to solve this by retrieving relevant documents, but they still dump everything into the LLM context without considering the order or relationships. But these approaches miss the fundamental issue they’re still treating the LLM as the primary decision-maker.
Worse, they’re creating new problems. Adding more context often causes LLMs to hallucinate and provide poorer results. These hallucinations aren’t just technical failures they’re potential legal liabilities. OpenAI, Microsoft, and Anthropic are already facing lawsuits for AI outputs that produce defamatory content or violate copyrights. UnitedHealth got sued for AI decisions with 90% error rates that allegedly caused patient deaths[¹]. When an AI agent makes decisions that violate regulations or create compliance issues, companies face real penalties.
What I Come Up With?
Recently, I have been building an AI agent orchestration system where developers enter plain language and the system handles agent creation and management. Building this system taught me firsthand why current approaches fail.
One of the first challenges I faced was integrating LLMs into the system. I had to implement different providers and connect them to a factory. At this point it’s almost ambiguous to know how many integrations will be needed tomorrow the landscape changes too rapidly.
Nevertheless, another issue arose from decision making. In each different run cycle, the system’s behavior was changing due to use of incapable models. After the upgrade it was partially working. This time the issue was context management. New models can take up to 1M tokens but this wasn’t the issue. The issue was providing the relevant data for decision making in a way that actually helped rather than hurt.
One point needs to be mentioned here is that this system was using threads to create agents in parallel. Such creation was creating dozens of system messages to be included in the prompt, which was bloating the context and confusing the LLM.
Context Maintenance
I came up with a different strategy and made the creation sequential. Any component in the system was responsible to register their state into the context in a sequential manner. This made decision making dramatically easier and more reliable.
The solution wasn’t just about reducing context size it was about the relations of these items in the context. When information flows in logical sequence, LLMs can follow the reasoning much more effectively.
Supporting Trends
One great example supporting my idea is KIRO. This is a new IDE created by Amazon and it brings new strategy to agent software development. It integrates pragmatic software development strategies into agentic software development. I know it feels weird, we are defining the wheel again. However, this is what it is right now.
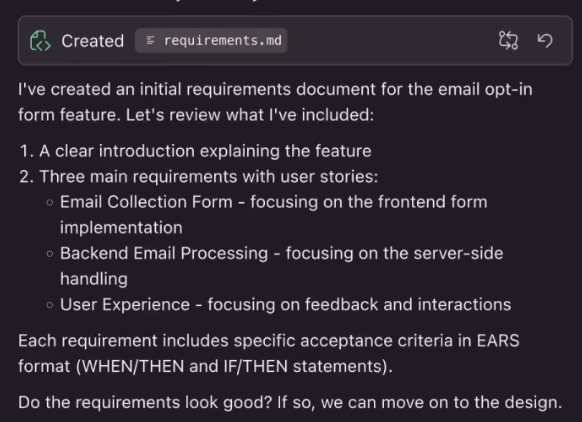
In this image, it’s shown that the agent forces developer to define requirements as the initial step. It identifies the request and prepares an action proposal. If the developer likes it, then it creates the plan to be executed in the next step.
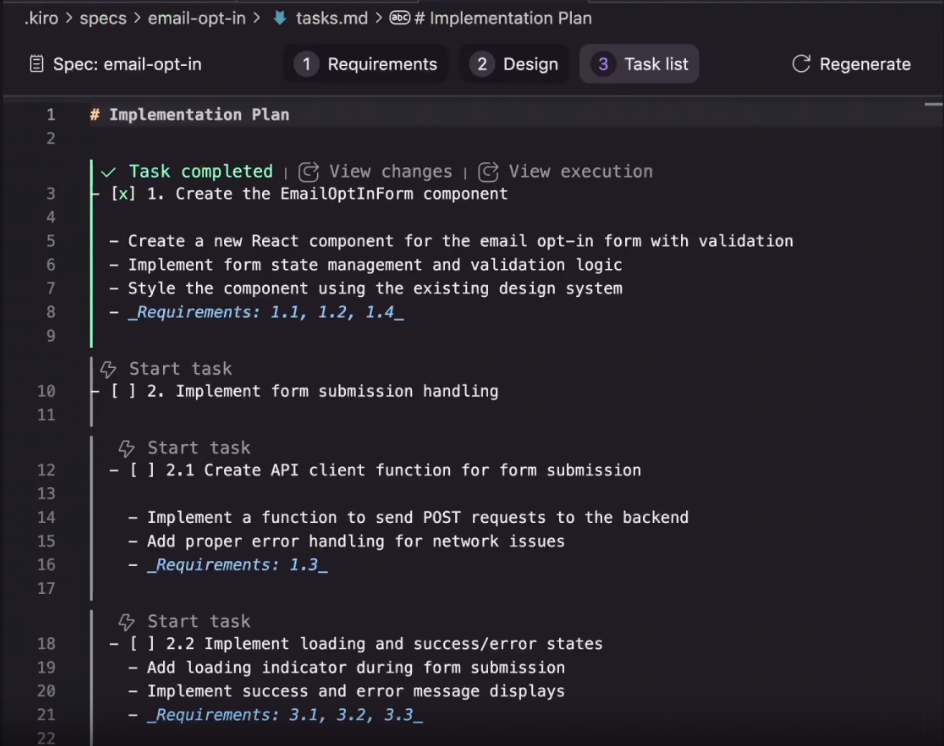
It creates tasks in sequential order as the developer wants them to be implemented, then the developer clicks on “Start task” and executes each one.
Academic Validation
Recently, I found research from Cornell that supports my approach. The “Chain of Agents” paper from June 2024 shows that sequential agent collaboration works much better than traditional methods up to 10% improvement[²].
What’s interesting is they discovered the same problems I faced. They mention that current approaches “struggle with focusing on the pertinent information” which is exactly the context management issue I was dealing with. Their solution uses “worker agents who sequentially communicate” and “interleaving reading and reasoning” very similar to my sequential pipeline approach.
The academic community has already started catching up to what practical experience shows. Structure and sequence matter more than just using more powerful models. It feels good to see research validating what I discovered while building real systems.
Conclusion
As KIRO suggests “Bring structure to AI coding with spec-driven development”, developing in structured form is not only for development but for most of the agentic workflows as my experience also suggests. This approach brings reliability and scalability into the systems because as reliability increases, there will be more to add on.
References:
[1] International Business Times. “Lawsuit Filed Before Killing: UnitedHealthcare CEO Accused Insurance Giant Of Using Faulty AI Tool.” Link
[2] Zhang, Y., Sun, R., Chen, Y., Pfister, T., Zhang, R., & Arik, S. Ö. (2024). “Chain of Agents: Large Language Models Collaborating on Long-Context Tasks.” arXiv:2406.02818. Link